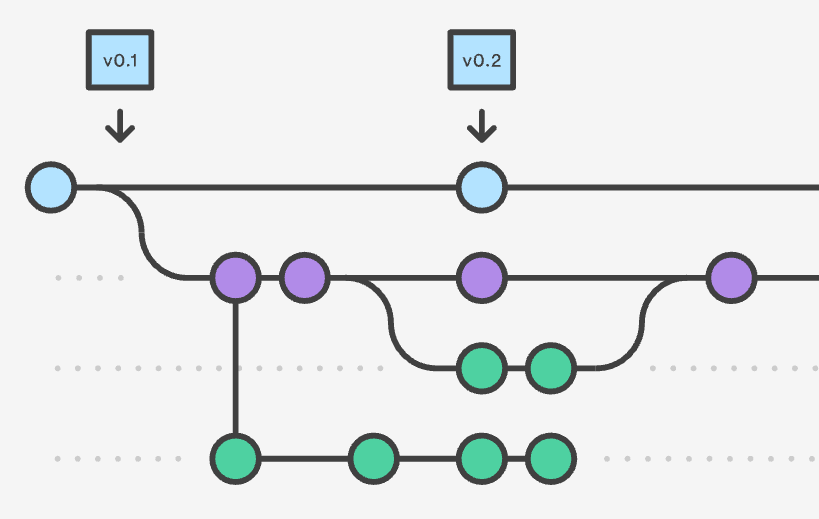
…. thus goes a famous nursery rhyme from our childhood. How is it relevant to version control? In this post, you are going to imagine yourself as an author of the afore-mentioned nursery rhyme, working with a few more colleagues. Using that example, we will see how version control software works.
Akshay is anxious to have cutlets. He can’t wait to sink his tooth into the cripsy, brown delicacies. He quickly boils some potatoes in a pot, mixes them hurriedly with some chilly, salt and pepper, pats the mixture into round shaped patties and sautes them on the pan greased with oil. Finally, he eats them. Oops. The potatoes are only half-boiled. He has added too little chilly, too much salt. The oil had not heated properly before Akshay tossed the cutlets in it for shallow frying. Some cutlets are still raw. Akshay thinks to himself: “Next time I should test the results after each step of cooking.”
Bharani is more methodical. She starts with a skewer. The skewer bounces off the surface of the potato. “So this is how hard they are”, she thinks, “They need a 10-minute boiling. After that, the skewer should go 2 inches inside”. After the potatoes are done, she tests with the skewer again and is satisfied with the texture. She mashes them and puts a small sample of the mash into her mouth. The bland taste gives her an estimate of how much spices should be added. She starts with a teaspoon of chilly and salt, kneads the mash well. After 10 seconds of mashing, she tastes a sample. She adjusts the chilly and salt as per her liking and then pats the mash into round shaped patties. Next she heats some oil on a pan. She waits until the oil sizzles. Then she drops a tiny piece from one of the patties and checks how it fries. The piece comes out golden brown and cripsy. Now Bharani is ready to lay all the patties on the pan. In the end, she enjoys some tasty cutlets.
One of the biggest technological advances in this decade is the usage of machines hosted by server giants like Amazon and Google for our businesses, in the form of AWS and Google Cloud Compute. Not only do these companies offer machines, but they also offer specific services such as databases, service to send SMS, online development tools and backup services. These services are collectively referred to as PaaS or Platform-as-a-Service.
Over the last two years, another new concept has rapidly caught, mainly thanks to Amazon’s Lambda. We call this FaaS or Function-as-a-Service, where instead of running an entire software program or a website throughout the day, we simply run a single function, such as sorting a list of million names or converting the format of 50 videos from MPEG to AVI, etc on a remote machine which stays on for only the duration of the time that our function runs and then shuts down. By not keeping machines running all day, maintenance and operational costs go down significantly. This particular way of running machines for a specific short-term purpose and then shutting them down is now termed as ‘serverless’ architecture. Continue reading “Serverless architecture”
In the last article Introduction to clean architecture: Part 1, we saw how clean architecture is a set of principles for designing software such that the purpose of a software program is clear on seeing its code and the details about what tools or libraries are used to make it are buried deeper, out of sight of the person who views it. This is in line with real world products such as buildings and kitchen tools where a user knows what they are seeing rather than how they are made.
In this article, we will see how a very simple program is designed using clean architecture. I am going to present only the blueprint of a program. I won’t use any programming language, staying true to one of the principles of clean architecture, i.e. it doesn’t matter which programming language is used.
The simple program
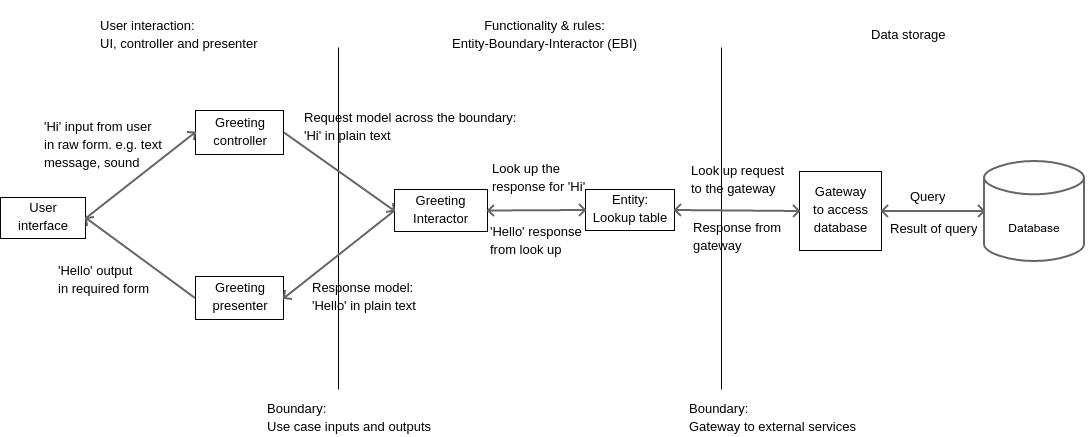
In our program, we will allow our system to receive a greeting ‘Hi’ from the user while greeting him/her back with a ‘Hello’. That’s all we need to study how to produce a good program blueprint with clean architecture.
Where do we start
I have outlined this in the post An effective 2-phase method to gather client requirements. When given a problem, we must always start with who the user are and how the system work from their points of view. Based on the users, we should build possible use cases.
In our system, we have a single user who greets our system. Let’s call him/her the greeter. Let’s just use the word ‘system’ to describe our greeting application. We have just one case in our system which we can call, ‘Greet and be greeted back’. Here’s how it will look.
The greeter greets our system.
On receiving the greeting ‘Hi’ (and only ‘Hi’), our system responds with ‘Hello’, which the greeter receives.
Any greeting other than ‘Hi’ will be ignored and the system will simply not respond.
This simple use case has two aspects.
It comprehensively covers every step in the use case covering all inputs and outputs. It distinctly says that only a greeting of ‘Hi’ will be responded to and that other greetings will be ignored without response. No error messages, etc.
The use case also has obvious omissions. The word ‘greet’ is a vague verb which doesn’t say how it’s done. Does the greeter speak to the system and the system speak back. Does the greeter type at a keyboard or use text and instant messaging? Does the system respond on the screen, shoot back an instant message or send an email? As far as a use case is concerned, those are implementation details, the decisions for which can be deferred for much later. In fact, input and ouput systems should be plug-and-play, where one system can be swapped for another without any effect on the program’s core working, which is to be greeted and to greet back.
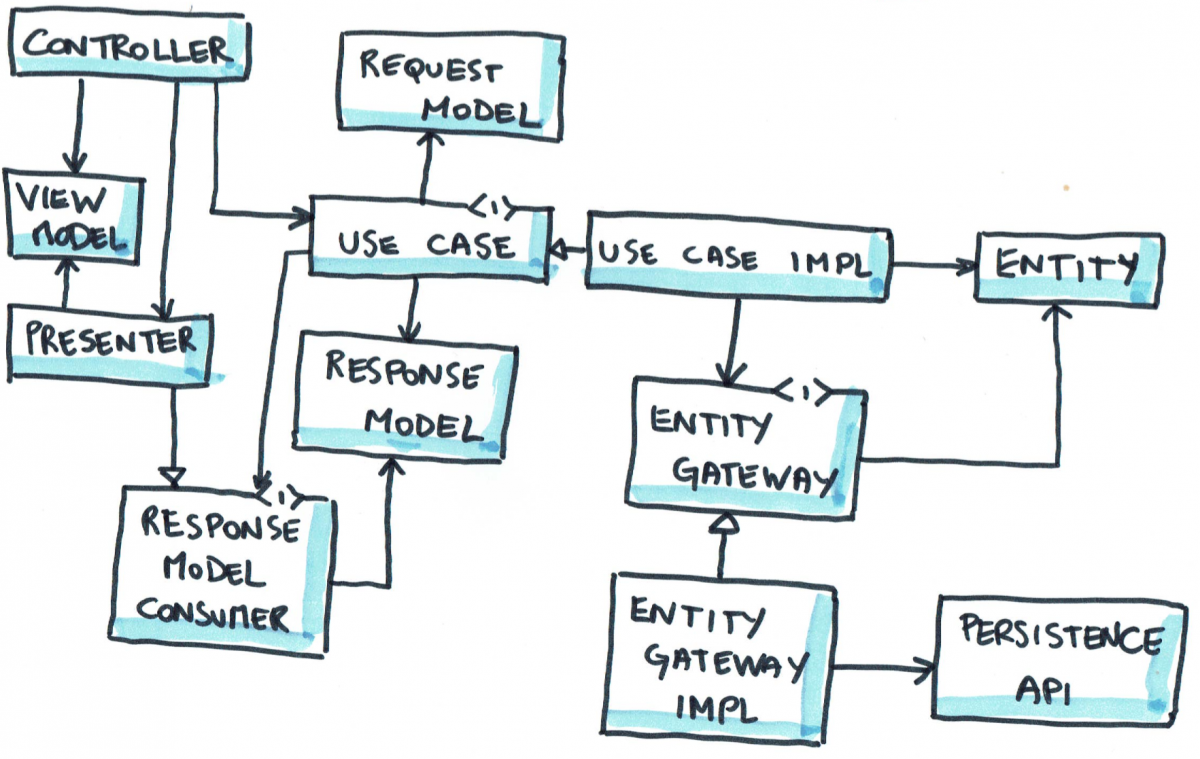
The EBI system
Components of clean architecture in our Greeting program.
Once the requirements are clear, we start with the use cases. The use case is the core of the system we are designing and it is converted into a system of parts known as the EBI or Entity-Boundary-Interactor. There are 5 components within the EBI framework. Every use case in the system is converted to an EBI using these five parts.
Interactor (I): The interactor is the object which receives inputs from user, gets work done by entities and returns the output to the user. The interactor sets things in motion like an orchestra director to make the execution of a use case possible. There is exactly one interactor per use case in the system.
Entities (E): The entities contain the data, the validation rules and logic that turns one form of input into another. After receiving input from the user, the interactor uses different entities in the system to achieve the output that is to be sent to the user. Remember that the interactor itself must NEVER directly contain the logic that transforms input into output. In our use case, our interactor uses the services of an entity called GreetingLookup. This entity contains a table of which greeting from the user should be responded to with which greeting. Our lookup table only contains one entry right now, i.e. a greeting of ‘Hi’ should be responded to with ‘Hello’.
Usually, in a system that has been meant to make things easy, automated or online based on a real world system, entities closely resemble the name, properties and functionality of their real world equivalents. E.g. in an accounting system, you’ll have entities like account, balance sheet, ledger, debit and credit. In a shopping system, you’ll have shopping cart, wallet, payment, items and catalogues of items.
Boundaries (B): Many of the specifications in a use case are vague. The use case assumes that it receives input in a certain format regardless of the method of input. Similarly it sends out output in a predetermined format assuming that the system responsible for showing it to the user will format it properly. Sometimes, an interactor or some of the entities will need to use external services to get some things done. The access to such services are in the form of a boundary known as a gateway.
E.g., in our use case, our inputs and outputs may come from several forms such as typed or spoken inputs. The lookup table may seek the services of a database. Databases are an implementation detail that lie outside the scope of the use case and EBI. Why? Because, we may even use something simpler such as an Excel sheet or a CSV file to create a lookup table. Using a database is an implementation choice rather than a necessity.
Request and response model: While not abbreviated in EBI, request and response models are important parts of the system. A request model specifies the form of data that should be sent across the boundaries when requests and responses are sent. In our case, the greeting from the user to the system and vice-versa should be sent in the form of plain English text. This means that if our system works on voice-based inputs and outputs, the voices must be converted to plain English text and back.
Controllers
With our EBI system complete to take care of the use case, we must realise that ultimately the system will be used by humans and that different people have different preferences for communication. One person may want to speak to the system, while another prefers instant messaging. One person may want to receive the response as an email message, while another may prefer the system to display it on a big flat LCD with decoration.
A controller is an object which takes the input in the form the user gives and converts it into the form required by the request model. If a user speaks to the system, then the controller’s job is to convert the voice to plain English text before passing it on to the interactor.
Presenters
On the other side is a presenter that receives plain text from the interactor and converts it into a form that can be used by the UI of the system, e.g. a large banner with formatting, a spoken voice output, etc.
Testability
Being able to test individual components is a big strength of the clean architecture system. Here are the ways in which the system can be tested.
Use case: Since the use case in the form of EBI is seperated from the user interface, we can test the use case without having to input data manually through keyboards. Testing can be automated by using a tool that can inject data in the form of the request model, i.e. plain text. Likewise the response from the use case can be easily tested since it is plain text. Also individual entities and the interactor can be seperately tested.
Gateway: The gateways such as databases or API calls can be individually tested without having to go through the entire UI and use case. One can tools that use mock data to see if the inputs to and outputs from databases and services on the Internet work correctly.
Controllers and presenters: Without involving the UI and the use case, one can test if controllers are able to convert input data to request model correctly or if presenters are able to convert response model to output data.
Freedom to swap and change components
Interactors: Changes to the interactors are often received well by the entire system. Interactors are usually algorithms and pieces of code that bind the other components together, usually a sequence of steps on what to do. Changes to the steps does not change any functionality in the other components of the system.
Entities: Entities are components that contain a lot of data and rules relevant to the system. Changes to entities will usually lead to corresponding changes in the interactor to comply with the new rules.
Boundaries: Boundaries are agreements between the interactor and external components like controllers, presenters and gateways. A change to the boundary will inevitably change some code in the external components, so that the boundary can be complied.
UI: With a solid use case in place, you can experiment with various forms of UI to see which one is most popular with your users. You can experiment with text, email, chat, voice, banner, etc. The use case and the gateway do not change. However, some changes to the UI can cause a part of the controller and the presenter to change, since these two are directly related to how the UI works.
Controller and presenter: It is rare for the controller or presenter to change in their own rights. A change to the controller or presenter usually means that the UI or the boundary has also changed.
Conclusion
Clean architecture seperates systems such that the functionality is at the core of the system, while everything like user interface, storage and web can be kept at the periphery, where one component can be swapped for another. Hopefully, our example has given you a good idea about how to approach any system with clean architecture in mind.
If you ever walk through the kitchen appliances section of a shopping mall, you will see lemon juicers made of steel, plastic and wood. The raw material doesn’t matter. One glance at the simple tool and you know what it is. The details about what the juicer is made of, who made it and how the holes at the bottom were poked become irrelevant.
Similarly, if you look at a temple, you know that it is a temple. A shopping mall screams at you to come shop inside. Army enclaves have tell-tale layouts, stern looking guards and enough signboards to let you know that you should stay away and avoid trespassing.
Once there lived a king whose land produced plenty of grains. The king made a policy to secure 1/5th of the produce and have it distributed to the poorest homes in his land for a subsidy.
The kingdom had a main distribution centre that was responsible for buying grains from the farmers and then distributing them to the local village distribution centres. Due to the sheer number of farmers and the number of villages to whom the grains were to be distributed, this main centre was overworked. Being busy, this centre would sometimes forget to reserve 20% for the poor neighbourhoods and send part of it to the regular villages. Sometimes, they would delay the distribution to the poor neighbourhoods.
The king wanted to change the system, ensuring that the poor got what they were promised. He set up a seperate distribution centre for the poor at the kingdom’s main temple. He instructed the farmers to take 1/5th of their produce to this centre and offer it to the kingdom’s chief deity at the temple. The rest of the produce was to be taken to the capital’s regular distribution centre. The temple’s distribution centre was immediately effective and the poor got the portion that they were promised for a subsidy.
What about OpenGL?
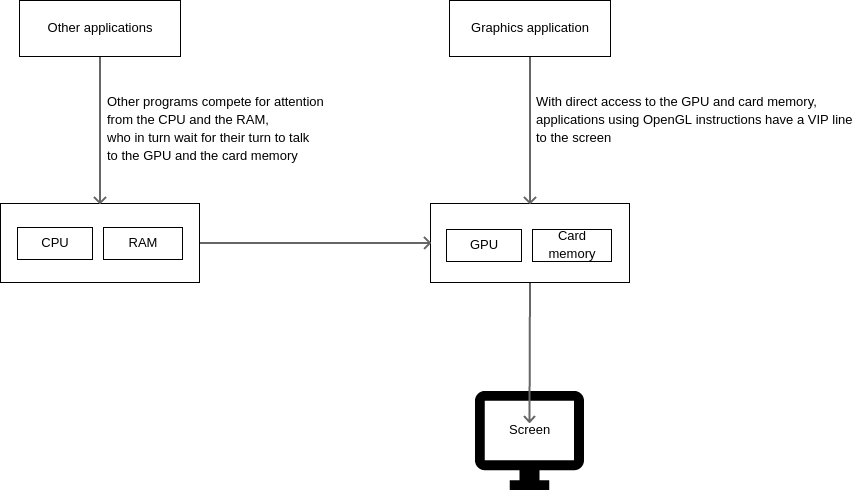
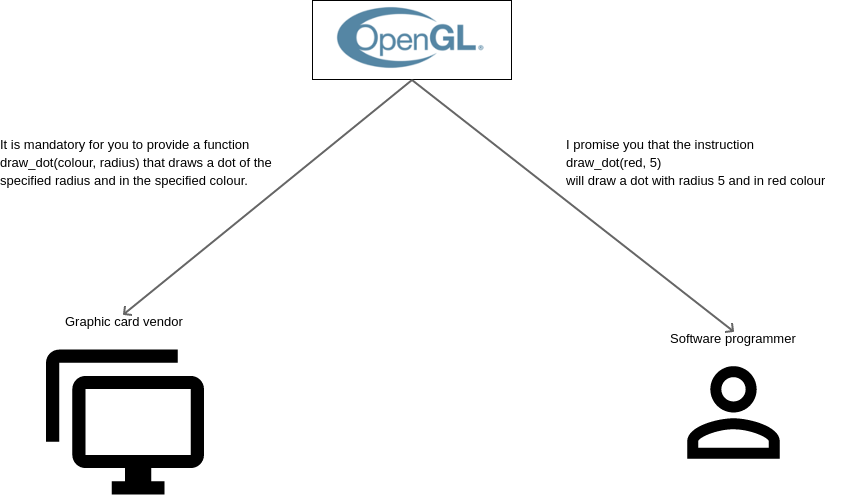
The moral of the story is that if you want something to be done on priority, then a seperate system must be set up for it. In computer graphics, OpenGL (Open Graphics Library) is a system that makes sure that apps forgo the computer’s main memory (RAM) and processor and instead use a seperate memory and processor (GPU or Graphics Processing Unit) inside the graphics card to which the screen is attached. The main memory and the CPU is where all applications compete for attention, but since drawing happens on the dedicated graphics memory and GPU, even the most complex of shapes on the screen are drawn very quickly, though you play an intense computer game with a lot of moving scenes.
How OpenGL works
What is OpenGL?
The world of computer graphics got really confusing in the 1990s when competing companies made competing solutions. None of the solutions were compatible with each other. One hardware would work with one app on one operating system, while not working on others. This made the progress of computer graphics really slow and cautious as graphics application makers were wary of permanently locking into a vendor for each solution. Everyone wanted some standards and interoperability.
At the end of the 1990s, companies that make software for developing apps (e.g. Google, Microsoft, Mozilla), companies that make operating systems (e.g. Microsoft, Apple) and companies that make graphics cards (e.g. NVIDIA, ATI, Intel) came together to make the Khronos group. This group made a set of specifications. The specification was a list of instructions that can be used by programmers and supported by operating systems and hardware for the most common drawing operations.
Instructions are as simple as placing a single dot on the screen or as complex as drawing 3-dimensional structures for an entire scene, complete with lighting and shadows. Instructions use the GPU and the dedicated memory provided on the graphics card made by the hardware vendors. The specifications are updated every year as the world of graphics evolves and more complex things are possible.
How OpenGL helps software programmers
Any specification or user’s manual creates an expectation about the set of things possible in a piece of technology. If you are given even an unbranded washing machine, you know that you can wash and dry clothes in it. Sure, there are semi-automatic machines and fully automatic models. But the behaviour is standardised. Put dirty clothes in, get them washed in water, get them dried and take out clean clothes.
The OpenGL specification creates expectations for the software programmers about a set of outcomes that a graphics system can achieve. Programmers are promised a set of instructions with what results to expect from them. The specification says that if they use instruction X, then it will lead to result Y. Since the OpenGL standard is adopted by multiple vendors, the programmers know that the same instructions will work on multiple operating systems and with multiple hardware vendors, as long as they promise to adhere to OpenGL.
How OpenGL specification standardises computer graphics instructions
Before OpenGL, there was no such standard and each hardware and operating system had their own unique instructions which didn’t work with others. Even the instruction to place a tiny dot on the screen would fail across multiple systems and programs were made for every system that the company wanted to support.
How OpenGL helps vendors
A company that makes washing machines knows that the customer expects a machine to do two things. Wash clothes in water and dry clothes by spinning. The vendor can provide other fancy details such as voice controlled input, temperature control of water or remote control through a smart phone. But if the machine doesn’t wash and dry, then its a failure. By default, the vendor is given those two goals for his/her product.
Vendors of operating systems and graphics cards are to provide at a minimum all the instructions that are specified by OpenGL. They have a goal to start with. They can add other fancy things that differentiate their product from others, but if they promise to adhere to OpenGL, then the instructions in the specification are to be mandatorily provided for.
Some companies are very savvy at graphics than others. These companies will make new breakthroughs in the field and will expect OpenGL to support those new features in the future. OpenGL allows vendors to package new features as extensions to the regular functionality, along with how to name those add-ons. Every year, vendor-specific extensions are reviewed by the OpenGL community and the most promising ones are inducted as new instructions in the specification. Every other vendor will need to support the new instructions too. Thus OpenGL provides a way for vendors to innovate and pave the way for the future.
Conclusion
From a chaotic mess of too many narrow solutions, OpenGL has united the community of computer graphics into an organised industry with standards. The computer graphics industry has promptly responded. From cartoonish 2-D characters that we saw in the 90s, on-screen characters have started resembling the real-world equivalents, complete with facial expressions and behaviour. As more vendors and programmers enter the field and virtual world mingles with reality, we can only watch in amazement as technology improves.
Adarsh is a young chocolate maker whose chocolate products, especially chocolate sauce, are extremely popular in town. His chocolate sauce is loved by retails shoppers and restaurant kitchens alike. Restaurants use his chocolate products as part of their own recipes such as sundaes. It’s a wonder, because Adarsh has been making chocolates for only two years. Food connoisseurs are impressed with Adarsh. They have been to his shop floor and they attribute his success to his meticulous attention to detail. One particular connoisseur, Bindia, writes for the ‘Foodies’ section of the town newspaper and is excited at the chance to interview Adarsh about his success. Here is how their interview goes.
Over the past decade, computer graphics have moved increasingly to the world of 3D. With the release of 3D graphics libraries like Unreal and Unity, more players are entering the game, figuratively and literally. But it takes a lot to change your perception from a 2D world to one of 3D. It is more than just adding a third axis named Z. We wouldn’t simply want to see flat 2D shapes floating around in our 3D world, would we?
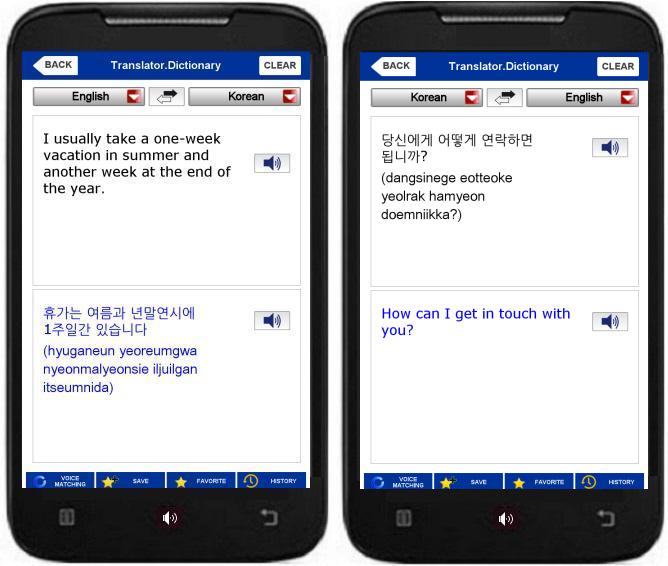
Khushi loves to write children’s stories. She has written several stories in English in her country India. Muskan, a friend of Khushi, works for Samsung. She goes on a business trip to South Korea and takes her young daughter along. She has some children’s books in one of her bags. A local colleague loves the book and asks Muskan if her friend can make the books available in South Korea in Korean.
Khushi is delighted at the opportunity and is ready for a trial book tour in Seoul, where she is to showcase three trial stories to South Korean children. If they love it, there’ll be a deal with a publisher. However she has a problem. She doesn’t speak a word of Korean. The children of South Korea aren’t comfortable with English. So Khushi has two choices. She can use help, translate the three stories into Korean and take the Korean versions with her so that the children can read them on their own. Otherwise she can seek someone in Seoul who speaks both the languages fluently. Then she can read the story line-by-line in English and the interpreter can translate each line into Korean for the children at the same time.
What does children’s books have to do with our topic today? There are two types of programming languages in software. Some of them use a compiler and some use an interpreter. Using the children’s books as an example, we will learn how the two work.
Compiler: When Khushi takes a translated book to South Korea
Khushi decides to do the hard work upfront. She hires a translator on Upwork and gets the three stories translated to Korean. She can then take the Korean books to South Korea and hand them to the children, who can read the books without help. She can take the Korean books to as many Korean communities as she likes, without having to look for a translator every time.
However, Khushi faces the following issues. On one hand, she needs to keep the English versions as her source products, whereas the Korean versions are her by-products. Instead of just 3 products (the original 3 stories), Khushi needs to maintain 6 products (including the 3 translations).
If Khushi finds the need to rewrite several parts of her stories, she must discard the Korean translations and have them done again. Thus, the process of translating beforehand is too sensitive to changes.
If someone invites Khushi to Netherlands, then the Korean translations are useless. She has to find a Dutch translator who will translate her books to Dutch. That will add 3 more products to her collection, taking the total to 9.
Finally, translation is a lot of work upfront. The entire book has to be translated from start to finish so that it can be used in South Korea. The time taken for translation will depend on the length of the stories and the complexity of the sentences used.
This is how a program using a compiler behaves. Let’s assume that you write your computer program in C or C++. A computer cannot understand either of those two languages. It can understand only something called machine language. Machine languages are different for different types of computers, just like Korean is to South Korea and Dutch to Netherlands. E.g. the machine language understood by a desktop computer is different from that of a mobile phone and that of a microwave oven. The microwave oven cannot understand the machine language meant for a desktop computer, the same way a Dutchman cannot understand Korean.
Once you write your program, you need to run a compiler to translate the program into the machine language of the target machine. You need to compile one copy for each type of computing device you wish to run the program on. You need to maintain each compiled copy along with your original program in C/C++. The original one is for you to develop and grow your program in the future, whereas the compiled versions are for distribution. As long as two machines understand the same machine language, you can use the same compiled version on both. This is similar to the way that Khushi can use the Korean translation at Seoul as well as Incheon, but not at Amsterdam.
Every time you make changes to your program, you need to re-compile to all the target machine language versions, discard the older compilations and distribute the new ones to the target machines.
Interpreter: When Khushi hires an accompanying translator within South Korea
In this scenario, Khushi does not get her book translated upfront. She takes the English book with her to South Korea with the promise that she will have an interpreter accompanying her all the time. She reaches this agreement with Netherlands too. As long as the two countries keep their end of the promise, Khushi does not need to get any translation done upfront. Her luggage to both the countries includes the three stories that she wrote in English. When Khushi reaches the target community in South Korea, she pulls out her stories and starts reading them line-by-line. As soon as she finishes reading a line, the interpreter speaks the whole line in Korean, thus reaching Khushi’s audience.
Khushi can makes as many changes to the stories as she likes. She is guaranteed that her latest version will be translated line-by-line during her next story-reading session.
But life isn’t all rosy with this approach too. Khushi needs to make absolutely sure that the target country has a translator available to her. Without the accompanying translator, her English books are just useless.
Also, Khushi needs a translator every time she wants to showcase her stories to the same community or different communities inside South Korea. Just because her translator translated her story orally line-by-line doesn’t mean that anything was recorded in writing. The line-by-line translation needs to be done all over again.
Finally, take the case of a country like Kenya or Congo. These countries are poor and translation is not a lucrative job. The quality of translators is usually mediocre, with limited vocabulary. The result may not do justice to Khushi’s hard work.
This is how interpreted languages like Javascript, Python and Java work. The program in the original language is directly copied to as many target machines as required without undergoing any compilation, with the promise that the target machines have the interpreter of the required programming language installed. The programmer can make as many changes as required and immediately copy the new version to the targets, which will use the new version during the next run.
If the target device does not have an interpreter for the programming language, then the whole program is useless. There is no way to run it in that device.
The program interpreter behaves similar to Khushi’s language interpreter. It converts the program instructions to machine language line-by-line, but doesn’t note down the translations. As a result, the conversion is done every time the program is run.
A hybrid approach
What if Khushi carries the English versions to South Korea, but the interpreter also notes down the Korean version at the same that she translates line-by-line. By the time the interpreter is finished translating to the first community, there will be a newly written Korean version that Khushi can simply distribute to the other communities in the same country. Khushi doesn’t have to get everything translated upfront before leaving for South Korea. Nor does she have to take her interpreter with her everywhere. Khushi needs to remember one thing. She needs to take her interpreter along when changes are made to a story. The interpreter can then note down the Korean translation of the new version of the story when reading it for the first time to a Korean community.
Modern interpreters behave this way. They read programs line-by-line and issue the converted machine language instruction to the processor. But they also note down the conversion into a special area called the interpreter cache. As long as the source program hasn’t changed, the interpreter will take instructions from the cache rather than reading from the source language and translating yet again.
Comparison of compilers and interpreters
Here is a tabular comparison of compilers and interpreters.
A compiler needs to be installed on the machine where the program is developed.
An interpreter must be installed on every machine that the program needs to run on.
The program in the source language, e,g. C/C++, must also be maintained only in the development machine.
The program in the source language must be present on every device where it is to be run.
The source program must be converted into a machine language translation, which must be copied to every device. This must be done for every type of computing device.
The source program is copied as it is to every device where it should run. The same source is copied to all types of computing devices.
The entire program must be converted to machine code up-front before copying to the target machine and running. For a huge program such as an operating system, this may take several hours.
The interpreter picks up one line from the program and converts only that line to machine code. This is done for every line until the entire program is interpreted.
Once a program is converted to machine code and copied to the target device, no more translation takes place.
Since the program exists in source form, the interpreter must translate every line every time. But if an interpreter has a cache, then it only needs to translate once.
Which approach should I use?
There is a reason why 99% of the programming languages today are interpreter-based. The developer needs to maintain only the program in the source code and does not need to learn the tools to convert it to machine language form. The onus of converting lies with the company that writes the interpreter for the various computing platforms.
There are two reasons why a developer would want to look at writing some modules in compiled languages.
If you are running your program on a device that has very little storage and memory, it may not be possible to fit the interpreter into a low-capacity disk and then load it into limited memory. A compiled program, which is already in machine code for that device, would not need the interpreter at all. This is similar to Khushi’s situation in Kenya where good interpreters aren’t available.
If you are running a program that needs to be really, really fast, then the cost of translating every line before it is executed will catch up to you and make the experience bad. You will never see video editors or 3-D modelling apps made in Java or Python. The delay in interpretation will visible cause the frame rates to drop below 25 frames per second and you will notice what is called ‘jank’, i.e. video frames being delivered slower than what the eyes perceive as motion. As a result, video applications or applications that need real-time response are always written in compiled languages. Directly reading machine code is much faster than interpreted code.
Conclusion
Compiler and interpreters follow two different approaches, but their goal is the same. Both convert a program from it source language to something that a computing device will understand. It’s just that a compiler does it with the approach of someone setting curd from milk, i.e. starting well in advance before the product is used, whereas the interpreter follows the approach of someone who chops herbs right before tossing them into a pan, just in time, so that they don’t go stale.
Consider that you are preparing for a party at your home. There are several tasks to be done. Walls are to be decorated, plates are to be washed, food is to be made ready and you may need an extra shoe rack for guests to leave their footwear. Most probably, you do not do everything alone. You get the help of the members of your household. In fact if the load is too much, then you even ask your friends for help.
When more people work on the tasks for organising a party, you get multiple things done parallely. But with more participation comes the need for co-ordination and communication. Some of the tasks may be related to each other, e.g. someone who has promised to wipe washed dishes and stack them on your shelf will need the one who washes dishes to complete his/her task first. Usually, one of the participating persons needs to stay on top of what gets done and who does what. He/she is like the captain of a sports team. When everyone smoothly communicates the status of his/her tasks and one or two persons are aware of each task’s status, things go on quite well despite the complexity.
Modern computers work the same way. They have multiple processors capable of executing multiple things at the same time. Even a single modern processor performs time slicing, i.e. divides its attention among several processes / threads at the same time. Processes need to communicate among each other. For this, they use a system called a message queue.